-

连接人,信息和资产
LGD模型构建一直是银行的难点,关键障碍在于LGD的数据缺失相当严重。
作者:相信未来
来源:泓策投研手札(ID:FinanceBao)
评级是艺术,但你废掉另一只腿科学,直接和我开聊艺术和分析框架我就难以信服了,两者不矛盾,你为什么不和我聊聊科学?前述文章中谈及了数据治理问题(大数据信用风险管理操作手册),以及内评模型验证问题(内部评级模型验证方法全解析),本文则详细叙述银行内评模型建模的全流程(债券评级模型有自身特征),欢迎来怼。
违约损失率,也就是当客户发生违约后,债项损失的程度,等于1-回收率。《巴塞尔协议》强调“估计违约损失率的损失是指经济损失”,而不是会计上的账面损失。经济损失要考虑回收成本和资金的时间价值,也就是利用合适的折现率计算祸首现金流的现值。所以《巴塞尔协议》下的违约损失率(LGD)为:
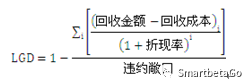
计算历史LGD的三个关键:回收现金流(有效催收窗口)、回收成本、折现率。
数据收集和变量构造
LGD模型构建一直是银行的难点,关键障碍在于LGD的数据缺失相当严重。LGD建模所需要数据可分为两部分:因变量和自变量计算所需要的数据。违约概率(PD)模型的数据缺失主要为自变量计算所需要数据的缺失,因变量(即违约与否的判断)数据质量相对较好,而LGD模型这两方面的数据缺失都相当严重。
历史LGD的计算数据,重点在于回收现金流、回收成本、折现率。关于回收现金流,各行都有催收台账,但是很少有银行在IT系统记录了详细准确的交易明细,成本分摊更是商业银行的软肋,准确地估计某个机构、某个时段、某个产品的回收成本几乎是不可能的。大型商业银行已经上线了标准催收、ERP等系统,这方面的情况有所改善。
自变量数据,包括债项类型、债项的优先级别、抵(质)押品、抵债资产的优先求债权、破产相关法律因素、行业因素、违约概率、商业周期、信贷历史、宏观经济等方面,其中,商业银行对于抵(质)押品的管理一直比较薄弱,数据积累也非常差,各大商业银行已经开始已经建设抵(质)押品市值重估和管理系统,数据情况得到改善。
穆迪的LossCalc™模型(Guptonand Stein, 2002)包括了债务类型和优先级、资本结构、行业、宏观经济四个方面的九个自变量。
穆迪LossCalc(TM)模型变量
变量类型 | 变量名称 | 变量数目 |
债务类型和优先级别 | 债务类型优先级别对应的LGD历史平均值 | X1 |
资本结构 | 债务的相对级别 资产负债率 | X2 X3 |
行业因素 | 行业回收率平均值 银行业指标 | X4 X5 |
宏观经济因素 | RiskCal模型计算的上市公司1年期违约概率中位数 穆迪破产企业债券指数 投机级债券12个月平均违约率 经济领先指数 | X6 X7 X8 X9 |
模型分组和样本选择
违约损失率LGD模型的分组基本上与客户违约概率评级模型的分组原则比较类似,一般可以从行业、规模、区域、产品等维度进行分组,具体应该选择几个维度,在每个维度如何分组,应该考察经济学直觉、业务管理情况、数据来源、统计分析等几个方面的情况。
违约损失率LGD模型必须要进行非违约账户和违约账户的分组,因为已经违约的客户包括了逾期后回收的更新数据,信息量远大于非违约账户,可以构造更多的自变量,预测也更为准确。
在非违约账户和违约账户分组中,LGD模型建设都只使用违约样本,但是观察期和表现期的构造不一致。非违约账户分组中,所有样本在观察点之前还没有发生违约,而在表现期内都发生违约,发生违约的账户回收率取决于有效催收窗口的分析,所以LGD模型的建设对于历史数据的时间长度要求比较高。
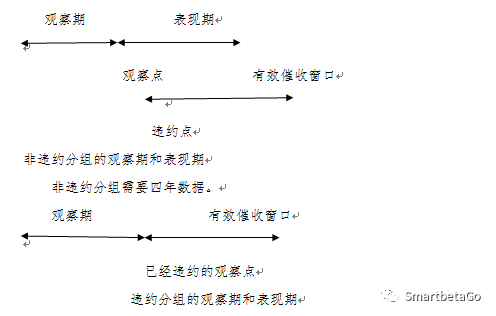
违约账户分组中,所有样本在当前观察点之前都已经发生违约,有效催收窗口在观察点之前已经开始,需要三年数据。
LGD分布特征
1、Beta 分布
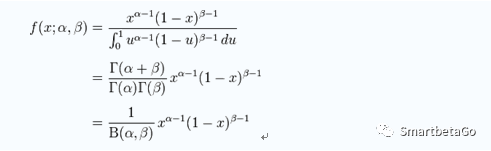
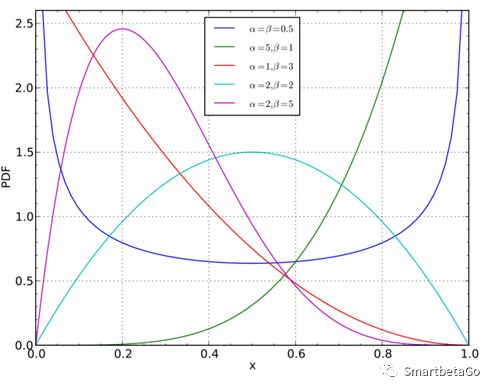
2、穆迪通过实证认为回收率服从Beta分布。
首先,回收率分布区间为[0,1]
Beta分布的形状随着两个参数的变化而呈现很大的差异,也能很好地拟合偏峰厚尾的情况。
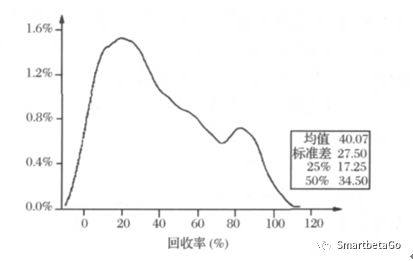
Moody公司1970-2002年第二季度间所有
债券和贷款回收率
LGD呈现的双峰分布(Bimodal Distribution),商业银行的信贷业务,双峰的情况比较严重。直觉上也比较容易理解,如果债务人主观上愿意还钱,无论时间长短,最终回归换大部分的借款,即违约损失率LGD比较低,呈现为低端的峰;如果债务人主观上没有意愿还钱,既然是违约,不如违约彻底,即违约损失率LGD比较高,呈现高端的峰。
特别对于中国商业银行,因为受国内坏账核销等法规和信用环境的影响,双峰分布更为极端,LGD取值0和1的情况占比非常大,也就是说,很多债务在催收后能全额还款,而有些债务则一分钱都没能回收。
双Beta函数的密度函数为
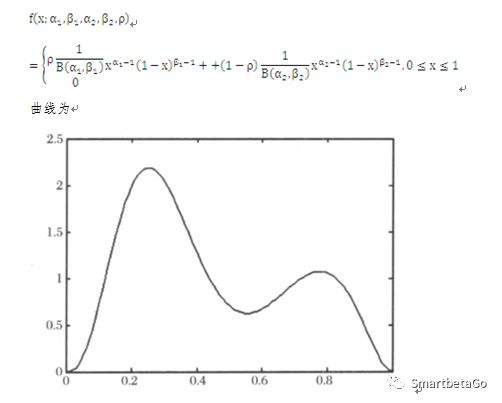
对于中国的商业银行,因为受到国内坏账核销等法规的影响,双峰分布更为极端,LGD取值为0和1的情况占比非常大:很多债务在催收后能全额还款,有些债务则分文收不回来。
模型方法论
理论上,没有绝对最优的模型方法论,其选择依赖于研究对象的数据结构和数据特性。违约损失率LGD数据的特点是:
1. LGD取值局限于[0,1],实证研究表明其分布为贝塔分布或双峰分布,总之不是正态分布,不适合使用线性回归模型。客户评级模型常用的Logistic回归是半参数方法,对于分布要求并不要个,能否使用LGD模型呢?
2. LGD取值在[0,1]连续,Logistic回归应用于分类问题,需要因变量离散变量,无法直接应用。
根据违约损失率LGD数据的特点,介绍三种模型方法:穆迪LossCalc™模型、构造样本Logistic回归、决策树。
(1) 穆迪的LossCalc™模型
穆迪的违约损失率LossCalc™模型基于回收率为因变量展开,由于回收率=1-LGD,所以无论是LGD还是回收率为因变量,没有什么本质区别。
(1-1) logistic模型
穆迪的违约损失率LossCalc™模型中迷你模型类似穆迪违约概率模型RiskCal的处理,即通过单变量分析得到自变量到历史平均LGD的转化函数。
(1-2) 分布转化
在回收率符合贝塔分布的情况下,可以通过分布转化函数将贝塔空间下的回收率R转化成正态空间下的回收率
在正态空间下,可以采用线性回归:
其中,Betadist(R)代表Beta分布函数
为迷你模型的输出结果作为回归模型的输入
(2) 构造样本Logistic回归
LossCalc™模型方法在LGD取值比较连续的时候比较有效,但是对于中国的商业银行业LGD分布在1和0点过多的情况,适用性有限。
如果LGD取值0和1比重非常高,可以采用Logistic回归方法,对于其中在区间(0,1)的值,可以采用如下构造样本的处理方法:
(2-1) 四舍五入法。顾名思义,就是LGD取值大于等于0.5的时候取值1,小于0.5的时候取值0.
(2-2) 样本权重法。四舍五入法的处理有点粗糙,只有双峰现象明显,LGD在区间(0,1)取值很少的时候才使用。样本权重法则精细一些,例如对于LGD取值为0.6的样本,构造LGD分别等于1和0的两个样本与其对应,然后在模型训练中,LGD=1的样本权重为0.6,LGD=0的权重为0.4。
(2-3) 虚拟样本法。例如对于LGD取值为0.6的样本,分别构造自变量形同的6个LGD等于1,4个LGD等于0的样本;对于LGD取值为1和0的样本,则需要负值10倍,以保证合理的样本权重。虚拟样本方法效果与样本权重法一致。
(3) 决策树
决策树属于非参数法,对于数据分布、数据类型都没有严格要求,比较适合处理LGD模型这种特殊情况。而且决策树方法也非常直观,逻辑判断过程在树结构中一目了然,易于业务人员接受。
【6.27-28成都站】个贷不良投资处置专题培训:市场趋势/评估尽调/交易结构/投后管理/处置全体系

【6.13-6.14深圳】重整投资特训营:预重整与庭外重组、房地产项目重整、破产收并购与上市公司重整实务

拿包+尽调+处置+法拍+精华案例全解析!

做好不良资产,学这一门课就够了!

2位深耕该领域的大咖老师领衔主讲,用特殊机会投资视角拆解困境上市公司重组重整中的巨大机遇。

全面掌握最新结构化融资技能!







